Aurich Lawson | Getty Images
I am now not an recordsdata scientist. And whereas I do know my formulation spherical a Jupyter pocket book and earn written an correct quantity of Python code, I develop now not profess to be the comfort shut to a machine studying expert. So once I carried out the principle share of our no-code/low-code machine studying experiment and bought higher than a 90 p.c accuracy charge on a model, I suspected I had achieved one thing terrifying.
Everytime you occur to haven’t been following alongside to this degree, proper here is a speedy consider sooner than I notify you attend to the principle two articles on this assortment. To hit upon how nice machine studying instruments for the comfort of us had developed—and to redeem myself for the unwinnable job I had been assigned with machine studying closing twelve months—I took a successfully-ancient coronary heart assault data residing from an archive on the School of California-Irvine and tried to outperform data science college students’ outcomes using the “straight ahead button” of Amazon Net Suppliers and merchandise’ low-code and no-code instruments.
The final degree of this experiment was as quickly as to spy:
- Whether or not a relative beginner could maybe maybe properly impart these instruments efficiently and precisely
- Whether or not the instruments had been extra cost-good than discovering any particular person who knew what the heck they had been doing and handing it off to them
That is now not exactly an correct describe of how machine studying initiatives usually occur. And as I stumbled on, the “no-code” chance that Amazon Net Suppliers and merchandise gives—SageMaker Canvas—is meant to work hand-in-hand with the extra data science-y formulation of SageMaker Studio. Nonetheless Canvas outperformed what I used to be as quickly as able to develop with the low-code formulation of Studio—although doubtlessly because of my a lot less-than-skilled knowledge-handling arms.
(For people who earn now not study the previous two articles, now’s the time to carry up: This is share one, and proper right here is share two.)
Assessing the robotic’s work
Canvas allowed me to export a sharable hyperlink that opened the model I created with my burly discover from the 590-plus rows of affected particular person data from the Cleveland Well being coronary heart and the Hungarian Institute of Cardiology. That hyperlink gave me barely extra notion into what went on inner Canvas’ very shaded subject with Studio, a Jupyter-essentially based mostly platform for doing data science and machine studying experiments.
As its title slyly suggests, Jupyter is in keeping with Python. It’s an internet-essentially based mostly interface to a container environment that lets you wander up kernels in keeping with fully completely different Python implementations, relying on the job.
Examples of the considerably a variety of kernel containers readily accessible in Studio.
Kernels will seemingly be populated with no matter modules the mission requires can earn to you could maybe maybe properly be doing code-focused explorations, such as a result of the Python Data Analysis Library (pandas) and SciKit-Be taught (sklearn). I used an space mannequin of Jupyter Lab to develop most of my preliminary data prognosis to save lots of on AWS compute time.
The Studio environment created with the Canvas hyperlink integrated some pre-built whine offering notion into the model Canvas produced—a pair of of which I talked about briefly within the closing article:
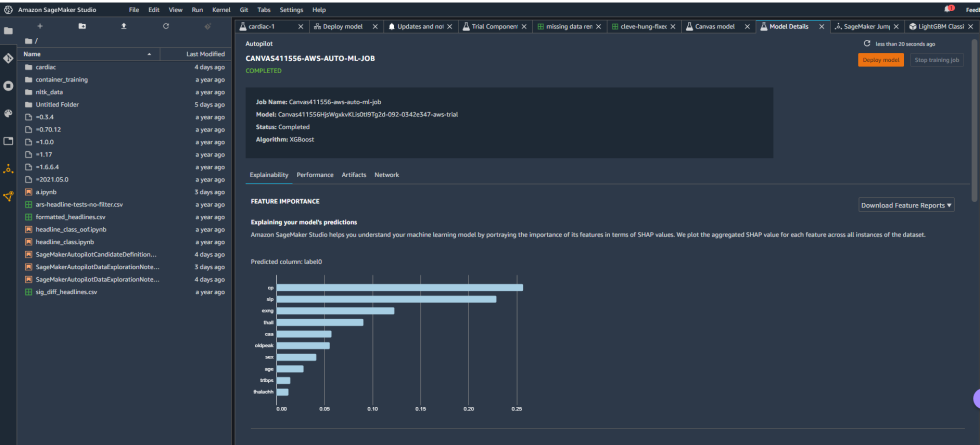
Construct bigger / Mannequin particulars from the Canvas handiest-of-note in Studio.
Only a few of the details integrated the hyperparameters utilized by basically essentially the most convenient-tuned mannequin of the model created by Canvas:
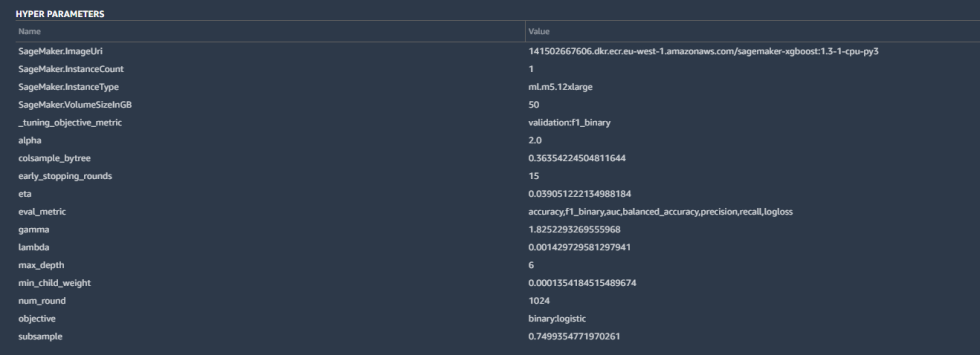
Construct bigger / Mannequin hyperparameters.
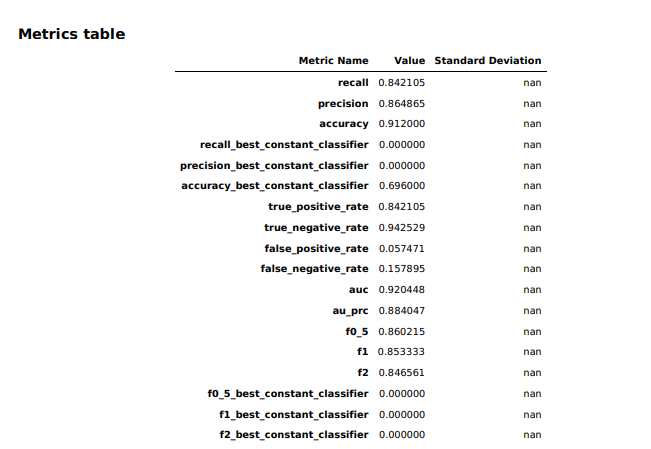
Hyperparameters are tweaks that AutoML made to calculations by the algorithm to toughen the accuracy, as efficiently as some elementary housekeeping—the SageMaker occasion parameters, the tuning metric (“F1,” which we’ll give attention to in a second), and different inputs. These are all ravishing common for a binary classification cherish ours.
The model overview in Studio offered some elementary data regarding the model produced by Canvas, along with the algorithm used (XGBoost) and the relative significance of each of the columns rated with one thing referred to as SHAP values. SHAP is a very terrifying acronym that stands for “SHapley Additive exPlanations,” which is a recreation theory-essentially based mostly formulation of extracting each data goal’s contribution to a commerce within the model output. Plainly evidently “most coronary heart charge achieved” had negligible have an effect on on the model, whereas thalassemia (“thall”) and angiogram outcomes (“caa”)—data capabilities we had necessary lacking data for—had extra have an effect on than I wanted them to. I might maybe no longer comely fall them, it appears. So I downloaded a efficiency describe for the model to search out extra detailed data on how the model held up: