
My Negate is now not my password —
Textual philosophize material-to-speech mannequin can withhold speaker’s emotional tone and acoustic ambiance.
Benj Edwards –

Enlarge / An AI-generated picture of a particular person’s silhouette.
Ars Technica
On Thursday, Microsoft researchers introduced a model distinctive text-to-speech AI mannequin generally known as VALL-E that may maybe properly fastidiously simulate a particular person’s articulate when given a three-second audio pattern. As soon as it learns a inform articulate, VALL-E can synthesize audio of that particular person asserting the remainder—and belief it in a strategy that makes an try to withhold the speaker’s emotional tone.
Its creators speculate that VALL-E will seemingly be vulnerable for glorious efficient text-to-speech capabilities, speech modifying the place a recording of a particular person will seemingly be edited and modified from a textual content transcript (making them philosophize one factor they earlier than the whole thing did no longer), and audio philosophize materials introduction when blended with different generative AI units fancy GPT-3.
Microsoft calls VALL-E a “neural codec language mannequin,” and it builds off of a talents generally known as EnCodec, which Meta introduced in October 2022. Not like different text-to-speech options that on the ultimate synthesize speech by manipulating waveforms, VALL-E generates discrete audio codec codes from textual content and acoustic prompts. It often analyzes how a particular person sounds, breaks that information into discrete elements (generally known as “tokens”) as a result of EnCodec, and makes make use of of teaching information to confirm what it “is acutely aware of” about how that articulate would sound if it spoke different phrases open air of the three-second pattern. Or, as Microsoft areas it within the VALL-E paper:
To synthesize custom-made speech (e.g., zero-shot TTS), VALL-E generates the corresponding acoustic tokens conditioned on the acoustic tokens of the three-second enrolled recording and the phoneme urged, which constrain the speaker and philosophize materials information respectively. At closing, the generated acoustic tokens are at chance of synthesize the ultimate waveform with the corresponding neural codec decoder.
Microsoft skilled VALL-E’s speech synthesis capabilities on an audio library, assembled by Meta, generally known as LibriLight. It accommodates 60,000 hours of English language speech from greater than 7,000 audio system, mainly pulled from LibriVox public area audiobooks. For VALL-E to generate a merely end result, the articulate within the three-second pattern should fastidiously match a articulate within the instructional information.
On the VALL-E occasion internet internet web page, Microsoft presents dozens of audio examples of the AI mannequin in motion. Amongst the samples, the “Speaker Urged” is the three-second audio outfitted to VALL-E that it should imitate. The “Floor Fact” is a pre-present recording of that very same speaker asserting a inform phrase for comparability capabilities (type of fancy the “administration” within the experiment). The “Baseline” is an occasion of synthesis outfitted by a standard text-to-speech synthesis blueprint, and the “VALL-E” pattern is the output from the VALL-E mannequin.
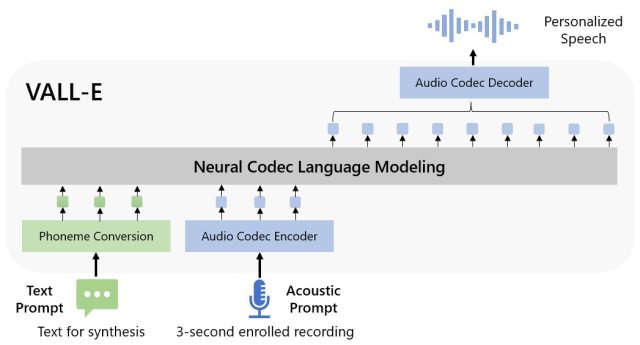
Enlarge / A block plot of VALL-E outfitted by Microsoft researchers.
Microsoft
Whereas using VALL-E to generate these outcomes, the researchers most interesting fed the three-second “Speaker Urged” pattern and a textual content string (what they needed the articulate to declare) into VALL-E. So study the “Floor Fact” pattern to the “VALL-E” pattern. In some conditions, the two samples are very discontinuance. Some VALL-E outcomes appear computer-generated, however others may maybe properly properly moreover doubtlessly be unsuitable for a human’s speech, which is the objective of the mannequin.
Furthermore protecting a speaker’s vocal timbre and emotional tone, VALL-E can moreover imitate the “acoustic ambiance” of the pattern audio. For example, if the pattern acquired right here from a phone name, the audio output will simulate the acoustic and frequency properties of a phone name in its synthesized output (that is a esteem blueprint of asserting this might moreover sound fancy a phone name, too). And Microsoft’s samples (within the “Synthesis of Vary” share) display that VALL-E can generate variations in articulate tone by altering the random seed vulnerable within the era course of.
Presumably owing to VALL-E’s ability to doubtlessly gasoline mischief and deception, Microsoft has no longer outfitted VALL-E code for others to experiment with, so we may maybe properly properly moreover no longer check out VALL-E’s capabilities. The researchers appear acutely aware of the doable social harm that this talents may maybe properly properly moreover inform. For the paper’s conclusion, they write:
“Since VALL-E may maybe properly properly moreover synthesize speech that maintains speaker id, it might perchance properly properly moreover elevate doable risks in misuse of the mannequin, truthful like spoofing articulate identification or impersonating a inform speaker. To mitigate such risks, it is possible to assemble a detection mannequin to discriminate whether or not or no longer an audio clip modified into as quickly as synthesized by VALL-E. We’re going to moreover place Microsoft AI Ideas into follow when additional rising the units.”